
Class 12 Biology Chapter 6 Molecular Basis of Inheritance The answer to each chapter is provided in the list so that you can easily browse through different chapters Assam Board HS 2nd Year Biology Chapter 6 Molecular Basis of Inheritance Question Answer.
Class 12 Biology Chapter 6 Molecular Basis of Inheritance



Also, you can read the SCERT book online in these sections Solutions by Expert Teachers as per SCERT (CBSE) Book guidelines. These solutions are part of SCERT All Subject Solutions. Here we have given Assam Board Class 12 Biology Chapter 6 Molecular Basis of Inheritance Solutions for All Subjects, You can practice these here.
(F). Long Answer Question (5 Marks):
Q.1. Give a brief account of DNA replication.
Ans : DNA replication takes place in the following steps :
(i) Activation of Deoxyribonucleotides : Deoxyribonucleotides such as DAMP, DGMP, DCMP, TMP floating freely in the nucleus serve as the raw materials. All these nucleotides are synthesised from precursor molecules formed from the metabolic products. The nucleotides are then activated by ATP which serves as energy source.
(ii) Uncoiling of Parent DNA Strands : The double stranded DNA helix uncoils to form single stranded DNA by breakage of weak hydrogen bonds. Enzyme helicase help in uncoiling the helix. Topoisomerase, another enzyme may also be responsible for cutting the DNA strand to facilitate uncoiling. As a result of uncoiling. A, T, G C bases become naked at one end. The naked ends project into nucleoplasm. Uncoiling at one end gives DNA strands a Y-shaped structure called replication fork.
(iii) Formation of RNA Primer : For the synthesis of new DNA strand RNA primer is formed in the DNA template. The enzyme primase catalyses the polymerisation of RNA. The RNA primer is removed after the fork is formed. The gap formed by the removal of primer is filled up by nucleotides.
(iv) Base Pairing : Once separation is completed, the nucleotides of separated chains start attracting their nucleotides or precursors from the environment within the cell. The precursor substances present in the nucleoplasm are triphosphates of deoxyribonucleosides such as deoxyadenosine triphosphate, thymidine triphosphate and so on. Each deoxyribose triphosphate splits off into deoxyribonucleoside monophosphate and two phosphate molecules. These deoxyribonucleotides bind with their complementary deoxyribonucleotides of any one of the two separated strands of parent DNA molecule by hydrogen bonds.
Thus deoxyribonucleotides from the nucleoplasm replace each of their complementary bases that are separated from it in the uncoiling process. According to Watson and Crick’s hypothesis only could couple to “T” base and “G” base could couple “C” and so on.
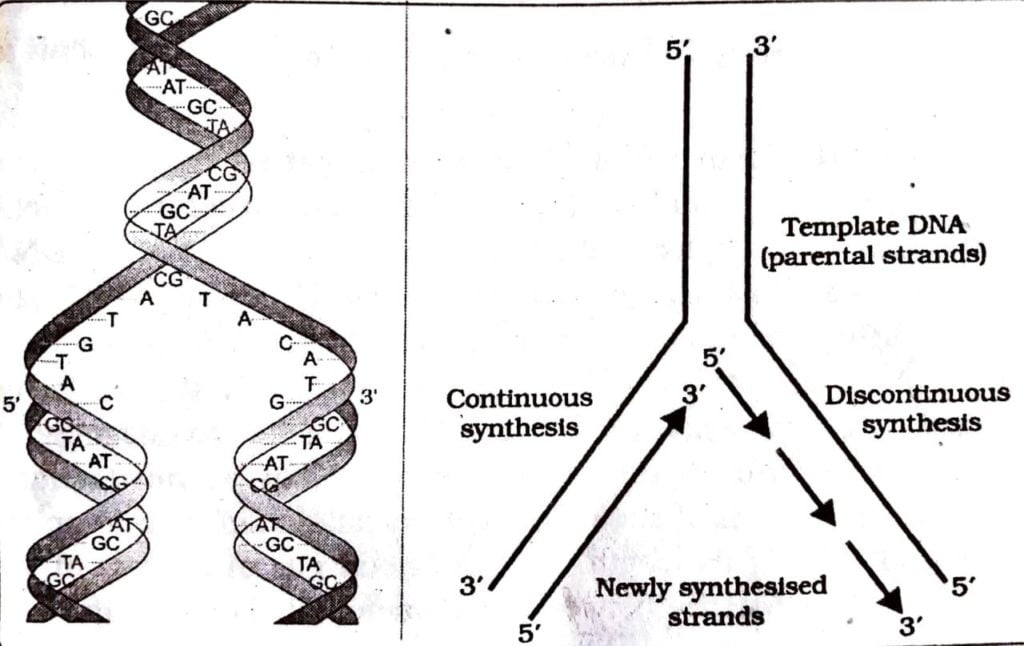
(v) Formation of New DNA strands : Newly formed nucleotides are attached to the nucleotides of the original strand of DNA molecule by hydrogen bonds. Adjacent sugar radicles also unite with one another by phosphodiester bonds. Thus two double helical molecules identical with each other are formed.
In this way the genetic code is faithfully transmitted from old DNA to new DNA. The deoxyribonucleotides are polymerised to form new DNA strand in the 5′-3′ direction. Because the two strands are antiparallel, the new strand forms in opposite direction. The new strand which is formed in continuous stretch in 5′- 3′ direction is called leading strand.
On the other parent strand short DNA segments form in the 5′-3′ direction starting from the RNA primer (in the fork end). This strand is known as okazaki fragment. The short fragments of DNA then join with the help of DNA ligase forming the lagging strand.
(vi) Editing and DNA Repairing : Accurate replication is ensured by DNA polymerase which remove the wrong bases that may be formed. The enzyme nuclease also remove the abnormal region of the DNA caused by mutation and then DNA ligase joins the repaired portion.
(vii) Helix Formation : Daughters and parent strand coil to form a double helix.
Q.2. Describe the structure of DNA with a neat labeled diagram.
Ans : Though different authors had described the structure of DNA differently but the most acceptable and convincing structure of DNA molecule had been illustrated by J.D. Watson and H.C. Crick (1953) by using X-ray diffraction photograph of DNA. The model as illustrated them is known as Watson and Crick’s structural model of DNA. It provided an idea of how a various constituents of DNA are attached to one another.
The model has the structure of a double helix formed bv polynucleotides. The helix has a diameter of about 20 A and each helix has one complete turn every 34A along its length. Each turn consists of a stack of ten nucleotides and so distance between each nucleotide is 3.4 A. In DNA molecule the adjacent deoxyribonucleotides are joined in a strand by phosphodiester bridges or bonds which link the ugar of one nucleotide to the sugar of the adjacent nucleotide.
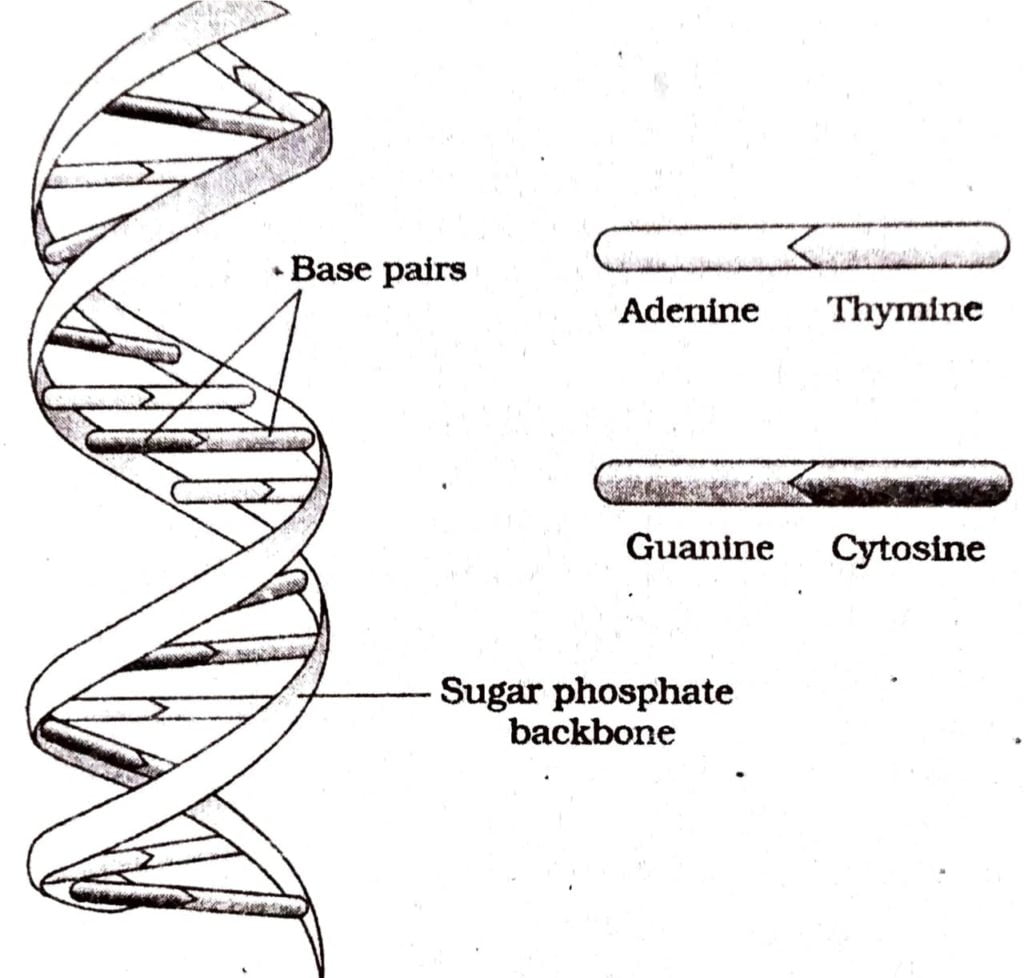
The molecule consists of two such polynucleotide chains remain twisted around each other to form a helical structure. The sugar and phosphate chain remain on the outside and thus form the back bone of each polynucleotide chain. The purines and pyrimidines remain on the inner side of the helix and face each other.
The two polynucleotide chains are held together by hydrogen bonds. The pairing of the nitrogenous bases of the two strands is very peculiar. The dimension of the purine rings is greater (due to double ring atoms in their molecules) than that of the pyrimidine ring (due to the single ring atoms in their molecules). So, to maintain constant diameter of the two-chains helix molecule of DNA, the purines always pair with pyrimidines with hydrogen bonds.
Because of the shape and chemical nature of the purine and pyrimidine bases, adenine can be attached only to thymine by two hydrogen bonds. Similarly guanine can be attached to cytosine by three hydrogen bonds. Therefore, four combinations of purine pyrimidine such as A-T,T – A, G-C and CG could only be found.
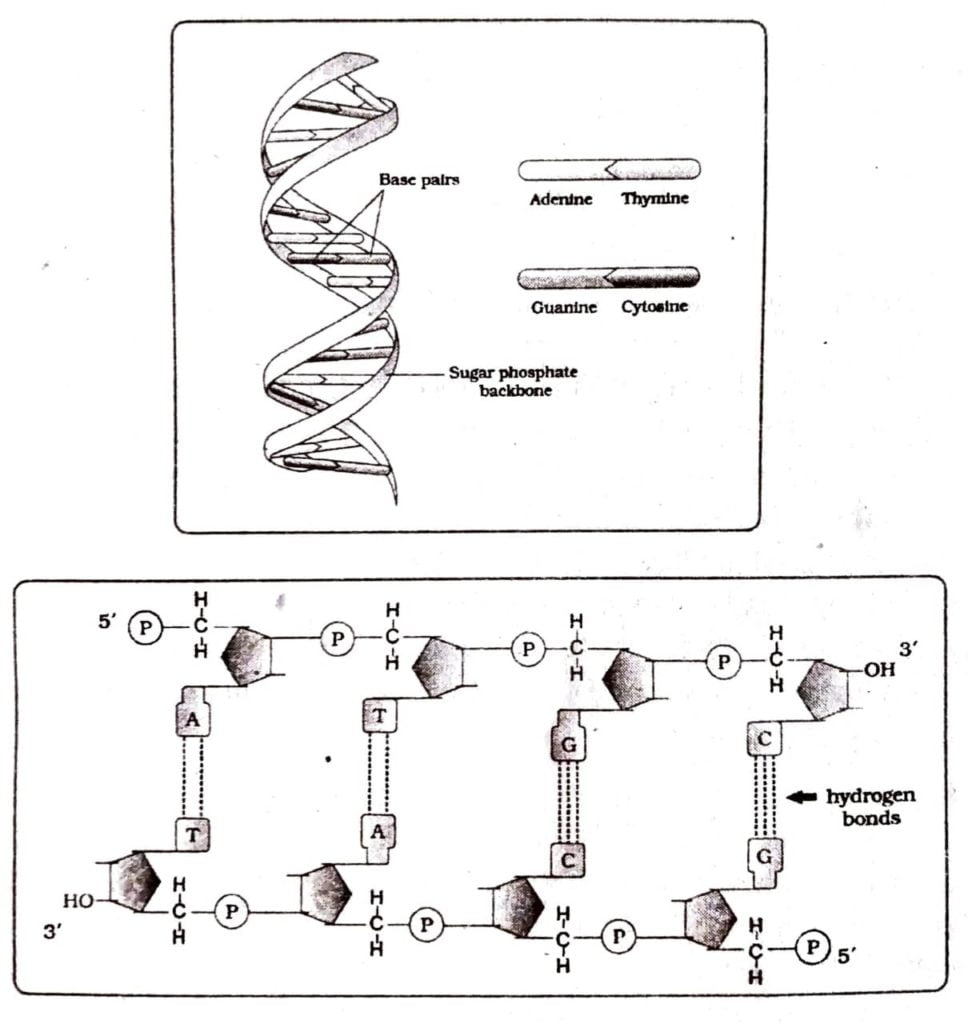
nucleotide of the other chain. Thus whatever the sequence of bases is present in one strand of the DNA molecule, a complementary sequence is present in other strand. Due to this type of base pairing, the two strands of DNA are not identical but complementary to each other. This is called complementary base pairing. The four base pairs may occur in infinite ways and thus provide infinite varieties of DNA molecules.
One end of the DNA strand is called 5′ end and the other end is called 3′ end. This is beçause the deoxyribose attaches itself to a phosphoric acid at 5 carbon position and the same deoxyribose attaches itself to the next phosphoric acid at 3 carbon position. This is called polarity of DNA.
The two nucleotide chains of DNA run in opposite or antiparallel direction. It means that in one chain the 5 carbon position in sugar molecule is in upward direction and in other chain its carbon position is in lower direction. This implies that if in one chain the direction is 5′-3′ and in other the direction is 3′-5′. This is known as antipara- llel direction of DNA molecules.
Q.3. Discuss how the DNA double helix packed to form chromatin in eukaryotes.
Ans : Exceptionally long DNA molecule is packed in such a way that it is 3. accommodated in the nucleus or the cell. The distance between two base pairs in mammalian DNA molecule is 0.34 nm (0.34 x 10⁹m). Now if the total number of base pairs in mammalian DNA is 6.6×10⁹ by the total length of mammalian DNA would be 6.6×10⁹hpx 0.34×10⁹/bp 2.2 meters. Such a long DNA molecule is packed in such a fashion that a large number of DNA molecule depending upon the number of chromosome (say for instance 46 DNA molecule in human cell) is packed within a single nucleus.
DNA is always linear and double stranded. Single DNA duplex makes a complex with basic protein called histone. This nucleoprotein complex is referred to as chromatin which is the unit of genome. The condensed form of chromatin is called chromosome. The nucleus of eukaryotic cells contains few or many chromosomes depending on the species. The size of chromosome varies from species to species. Therefore the size of DNA molecule is also variable.
The largest chromosome of Drosophila however contains a DNA molecule of about 4.0 cm long with molecular weight of 80 x 109 rearly 40 times larger than the DNA of E coli. The DNA of the eukaryotic cells undergoes folding and supercoiling many times to accommodate themselves within the chromosomes. The physical forms of chromosomes also varies according to the cell cycle. During interphase, they are extended or uncoiled. During prophase, chromosomes coil and shorten until they finally reach the metaphase.
During telophase they begin to uncoil and again attain the relaxed condition when the interphase of the next all cycle is reached. Therefore, change of physical form of chromosome during cell cycle possible brings some additional changes of folding and supercoiling pattern of DNA which is present inside the chromosome. It has been calculated that human chromosome No.13 contains a DNA molecule which is about 32000 pm long. This DNA undergoes looping supercoiling form a chromatid about 6 pm long and 0.8 pm in diameter.
Q.4. How Meselson and Stahl proved that DNA replication is semiconservative?
Ans : In 1958 Mathew Meselson and, Franklin Stahl performed the following experiment to show that DNA replicates.
(i) They cultivated E. coli in medium having ¹⁵NH₄ CI as the only nitrogen source and obtained the E. coli population containing “N labelled DNA. This ¹⁵N containing heavy DNA molecule could be distinguished from normal DNA molecule which was not labelled with N₁₅ by centrifugation in cesium chloride density gradient. This proves that the replicates are derived from parental DNA.
(ii) Next, they transferred the E. coli cells containing 15N labelled DNA of the earlier experiment into medium containing less dense isotopic nitrogen and allowed E. coli to multiply several generations. After first generation they could isolate hybrid DNA (¹⁵N to ¹⁴N)

One strand in ¹⁵N and the other is ¹⁴N the cells of the second generation the 50% “N-DNA and 50% hybrid.DNA could be founds. If samples are taken in subsequent generation, the ¹⁴N-DNA will produce true ¹⁴N-DNA but the hybrid DNA will again produce 50% ¹⁴N-DNA and 50% hybrid DNA. It takes 20 minute for DNA to replicate. This experiment is a proof of semi conservative model of DNA replication.
Q.5. Discuss the process of translation in detail.
Ans : During this process, proteins are formed by the ribosomes on the mRNA strand. The genetic information present in mRNA directs the sequential order of the specific amino acids to form a Polypeptide chain’. The main steps of translation are:
(a) activation of amino acids.
(b) attachment of activated amino acids to tRNA.
(c) initiation of protein synthesis.
(d) elongation of the polypeptide chain. and
(e) termination of the chain.
(a) Activation of Amino Acids : The first step in translation is the activation of amino acids. ch of the 20 amino acids of the cytoplasm occurs in inactive or dormant stage and they cannot like part in protein synthesis. The activation is facilitated by ATP. Each of the amino acid is catalysed by its own specific activating enzyme – aminoacyl synthetase. The free amino acids act with aminoacyl synthetase in presence of ATP to form aminoacyl adenylate and phosphopyruvate.

(b) Attachment of Activated Amino Acid to tRNA: The activated amino acids cannot reach he polyribosome to form polypeptide chain as they are intimately bound to enzymes. The Gated amino acid is transferred to its specific tRNA and attached with tRNA molecules. The transfer of the activated amino acid to tRNA is also specific. As a result of attachment of amino acid to a specific tRNA molecule, aminoacyl-tRNA is formed which can be shown as :

The aminoacyl-tRNA complex moves towards the polyribosome to initiate the protein synthesis.
(c) Initiation of Protein Synthesis : In E. coil, the messenger RNA forms the 70 S complex ith F-met tRNA and GTP. The mRNA has the first codon as AUG at the beginning and so it is own as initiation codon. There are three initiators, F1, F2 and F3 which get attached to the 30 S subunit of ribosomes. F1 and F2 factors along with GTP are required for binding of F-met-tRNA the small subunit. The AUG codons are the codes for the methionine. The methionine has ry important role in protein synthesis as it is the amino acid which starts the protein synthesis. !The initiation of protein synthesis takes place through a specific methionyl-tRNA complex known as F-met-tRNA.
The binding of F-met-tRNA with mRNA-30 S subunit requires the Initiation factors (F1 and F2) and GTP. The UAC anticodon of F-met-tRNA binds to AUG codon of mRNA. In every type of protein, formyl methionine occupies the first place in the molecule and when the protein molecule is synthesized completely, formyl methionine detaches from it.
(d) Elongation of the Polypeptide Chain : Elongation of polypeptide chain involves t regular addition of amino acids and relative movements of ribosome and mRNA in the presence of GTP so that a new triplet codon remains available for new aminoacyl tRNA. Elongation the polypeptide chain requires elongation factors which are EF-Tum EF-G and EF-TS in prokaryotic cells and EF-1 and EF-2 in eukaryotic cells. The site where the entry of amino acid takes place is called “A” site or aminoacyl site and the site in which nascent polypeptide chain remains is called “P” site or peptidyl site or exit site of tRNA molecule.
The next step of this process is translocation which comprises the discharge of unloaded tRNA from the P site. All the sequence of events occur very rapidly as the polypeptide chain of about 40 amino acids is produced within 20 seconds.
(e) Termination of Polypeptide Chain : After the polypeptide chain is formed according to e codon of MRNA, the process of termination and release of polypeptide chain occurs. The polypeptide chain elongates until a termination codon on mRNA is reached. The termination of the polypeptide chain is indicated by three special termination triplets in the mRNA. These triplets codons are UAA, UAG and UGA in prokaryotic cell. These are called nonsense codons which do not collaborate with any codons.

Q.6. Discuss the various application of DNA fingerprinting.
Ans : The HGP will enable the scientist to know for the first time how a chromosome looks like and its entire constituents. The knowledge that will emanate from the project will be used for centuries to come. The discovery of the genetic make up of chromosome will surpass any other discoveries of the past. It has more implications than sending on the moon and can be compared to the invention of wheel, that changed the world. Scientists are yet to know full implications of the knowledge that may be generated by the project. At present the scientist are optimistic about the application of the knowledge in the following cases:
(i) At present human beings suffer from a large number of inherited diseases which have no remedy. Disorder in a simple gene can give rise to 3000 different hereditary disorders, many of which cripple millions of healthy and productive lives and others are not so pronounced.
(ii) The cause of the dreaded disease – the cancer may soon be unfolded with the identification of the cancer gene.
(iii) The genomic study will help understand why human beings differ in physical structure, colour, height and why some are resistant to certain diseases and other are not.
(iv) Why human races are different in response to environmental tolerance, food habit, mental apptitude and why some races are more prone or resistant t certain diseases.
(v) The final frontier of genomic study is to understand the mystery that lie in the fertilized egg. How the fertilized egg knows to give rise to so many different types of cells to produce different organs like brain, muscles, vessels, heart, lungs skin, eyes etc. and the genes responsible for such differentiation.
(vi) To utilise the knowledge to improve health of people and to make a healthy society.
Q.7. Write the salient goals of Human genome Project.
Ans : The goals of Human genome projects are :
(i) Genetic Map : 2 to 5 cm resolution map (600-1500 marker)
(ii) Physical Map : 30,000 sTss.
(iii) DNA Sequence : 95% of gene containing part of Human sequence finished to 99.99% accuracy.
(iv) Capacity and Cost of Finished : Sequence 500 Mb/year at <$ 0.25 per finished base.
(v) Human Sequence Variation : 1,00,000 mapped human SNPs.
(vi) Gene Identification : Full length human c DNAs (chromosomal DNA).
(vii) Model Organisms : Complete.
Q.8. Discuss the methodologies involved in Human Genome Project.
Ans : The methods involves two major approaches. One approach focused on identifying all the genes that are expressed as RNA (Referred to as Expressed sequence Tags (ESTS)). The other took the blind approach of simply sequencing the whole set of genome that contained all the coding and non coding sequence, and later assigning different regions in the sequence with function (term referred sequencing, the total DNA from a cell is isolated and converted into random Fragments of relatively smaller sizes and cleaned is suitable hast using specialized vectors.
The cleaning resulted into amplification of each piece of DNA fragment so that it subsequently could be sequenced with case. The commonly used hosts were bacteria and yeast. The vectors were could Bacterial Artificial Chromosome (BAC) and Yeast Artificial Chromosome (YAC).
The fragments were sequenced using automated DNA sequencer that worked on the principle of a method developed by Frederick sanger. These sequences were than arranged based on some overlapping regions present in them. This required generation of over lapping fragments for sequencing. Alignment of these sequences was humanly not possible. Therefore specialized computer based programmes were developed. These sequences were subsequently annotated and were assigned to each chromosome. The sequence of chromosome 1 was completed only in May 2006.
Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites.

Q.9. Give five salient features of human genome project.
Ans : The salient features of human genome project are:
(i) The Human genome contains 3164.7 million nucleotide bases.
(ii) The average gene consists of 3000 bases, but sizes vary greatly.
(iii) The total number of genes is estimated at 30,000 much lower then the previous estimates of 80,000 to 1,40,000 genes. Almost (99.99%) nucleotide bases are exactly the same in all people.
(iv) The functions of absent 50% discovered genes are unknown.
(v) Less than 2% of the genome codes for proteins.
(vi) Repeated sequences make up very large portion of the human genome.
(vii) Repetitive sequences are stretches of DNA sequences that are repeated many times, sometimes hundred to thousand times.
(viii) Chromosome-I has most genes (2968) and Y has the fewest (231).
(ix) Scientists have identified about 1.4 million locations where single base DNA differences occur in humans.
Q.10. Discuss in detail the lac operon developed by Jacob and Monod.
Ans : Jacob and Monod in 1961 first provided with a model of Lac operon. An operon is defined as several 4 genes situated in tandem, all controlled by a common structural gene having repressor, promoter and operator. The message produced by an operon is polycistronic because the information of all structural genes resides on a single mRNA molecule. The lac operon (lac refers to lactose) consists of one regulatory gene (i gene) and three structural genes (Z, Y and A).
The i gene codes for repressor of the operon. The Z genes codes for beta galactosidase which hydrolyses lactose into galactose and glucose. They Y gene codes for permease which increase permeability of cells to beta-galactosidase. A gene codes for transacetylase whose function is not definitely known. This shows that three genes are required for metabolism of lactose.
The above fact shows that presence of lactose switches on the operon for synthesis of enzyme beta-galactosidase inside cells. It therefore acts as inducer. The permease facilitate entry of lactose inside cell. The i gene synthesises repressor. The repressor protein binds with the operator to prevent transcribing operon by RNA polymerase. The repressor is then inactivated by the inducer (such as lactose). This in turn allows RNA polymerase access to promoter and then transcription starts.
Q.11. How did Griffith explain the transformation of R-strain bacteria to S-strain bacteria.
Ans : Many suspected that DNA may be the genetic material. But this was not conclusive. The experiment of Griffith in 1920 with Streptococcus pneumoniae inspired many others to work in similar line with a view to unfold the mystery regarding the genetic material. S. pneumoniae is known to cause pneumonia. Griffith selected two types of pneumococcus. One type called smooth type or S-type, causes disease (virulent). It had capsule around its body, The other type, called rough type R-type was without capsule and was not virulent (avirulent). He first worked with the virulent and avirulent type by injecting both the types separately in separate mice.
Naturally the virulent bacteria (S-type) killed the mice while the non-virulent bacteria (type) could not. He then killed another sample of the virulent bacteria by heat treatment a injected the same in mice. This time he noticed that the mice survived. He also could not isola any such bacteria from the mice which survived after injection of heat killed virulent form. But he was astonished to find that when the heat-killed virulent form and living avirulent forms we mixed and the mixture was injected, the mice died.

It was a big question, how avirulent bacteria turned to be virulent and killed the mice while the virulent bacteria that were injected along with it were dead. Not only this, the bacteria isolated from dead mice showed that the non-capsulated avirulent type became virulent and capsulated type. It indicated that the non-virulent, non-capsulated bacteria acquired the genetic character of virulent, capsulated bacteria within mice.
Further research showed that such transformation of genetic character takes place even in culture plate when both types are placed together indicating that the mice tissues have no role in transformation of genetic character in bacteria. It was known further that the extract prepared by killing and crushing the virulent form could also convert non-capsulated, avirulent form into capsulated, virulent form. This indicated that something must- be there in the extract which has transmitted the genetic character.
Q.12. Draw a labelled diagram of the double helical structure of a DNA strand.
Ans :
Q.13. Explain the southern blot hybridization technique of DNA fingerprinting.
Ans : To know the technique one should have prior knowledge of DNA structure, replication and base pairing. Forensic science encounter with problem like identification of culprits from the blood stain, hair, skin or any other minute body parts left at the site of the crime. It may also be necessary to ascertain parenthood of one controversial child. In such cases a forensic expert takes the help of southern blot technique. We know that there is a large amount of “junk DNA”- DNA that does not code for protein-in the human genome. Junk DNA is made up of repeated sequences that are called repeats.
Although individuals may have identical genes, there may be different numbers of repeats between these genes. For example, one person may have 7 while another has 12. The more repeats, the longer the junk DNA between genes. One method of DNA fingerprinting- which produces a Southern Blot – begins by taking a DNA sample from something such as skin, saliva, blood, or hair. The DNA is cut into pieces using restriction enzymes. The resulting collection of DNA pieces will consist of some pieces of junk DNA and some genes. The sample DNA pieces and placed into a clear gelatin, where an electric current pushes the DNA pieces through the gel.
Short pieces move farther than long ones, so a piece of DNA that had 7 repeats would move faster than a piece of DNA with 12 repeats. Since DNA has no color more steps must be completed so scientists can “see” particular DNA pieces. The sequences are denatured so only a single strand remains. They are transferred onto a nylon sheet where the strands are permanently fixed. A radioactive probe with a known sequence is then added.
After a radioactive probe of single stranded DNA has been allowed to bond by base pairing with the denatured DNA on the paper an X-ray reveals only the areas where the radioactive probe sits. These are the only things that will show up on the film. This allows researches to identify, in a particular person’s DNA, the occurrence and frequency of the particular genetic pattern contained in the probe. This is then match with the DNA of suspected persons or their close relative to pinpoint the offenders.

Hi, I’m Dev Kirtonia, Founder & CEO of Dev Library. A website that provides all SCERT, NCERT 3 to 12, and BA, B.com, B.Sc, and Computer Science with Post Graduate Notes & Suggestions, Novel, eBooks, Biography, Quotes, Study Materials, and more.


